



Next: Ejemplo
Up: Encontrando todos los vecinos
Previous: Encontrando todos los vecinos
Índice General
Introducimos una técnica que acelera el proceso
para encontrar los 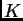 vecinos más cercanos de todos los elementos
de una base de datos, la idea es indexar este conjunto de puntos con un
algoritmo de pivotes como el FQTrie conservando las ventajas del
FQA y mejorando algunas de ellas, además la complejidad de este
algoritmo es lineal en su construcción, posteriormente usar está
para encontrar los vecinos más cercanos de cada punto.
vecinos más cercanos de todos los elementos
de una base de datos, la idea es indexar este conjunto de puntos con un
algoritmo de pivotes como el FQTrie conservando las ventajas del
FQA y mejorando algunas de ellas, además la complejidad de este
algoritmo es lineal en su construcción, posteriormente usar está
para encontrar los vecinos más cercanos de cada punto.
La idea principal del algoritmo es, realizar una consulta de rango con un radio 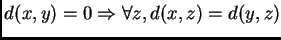 , para cada elemento,
es decir, se hacen
, para cada elemento,
es decir, se hacen 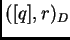 consultas de rango con radio r,
es importante enfatizar que para cada punto se utilizan los mismos pivotes
usados para generar el índice.
consultas de rango con radio r,
es importante enfatizar que para cada punto se utilizan los mismos pivotes
usados para generar el índice.
La estructura auxiliar (cola de prioridad) usada para el desarrollo
del algoritmo consiste en mantener para cada punto
al menos los elementos más cercanos durante el
proceso, manteniendo un radio máximo, el cual
corresponde al elemento más alejado y es precisamente el que esta
en el tope de la cola de prioridad. Como primer paso la cola de prioridad
es inicializada usando los pivotes (puesto que estos puntos conocen
todas las distancias a los demás puntos, véase la figura
![[*]](file:/usr/share/latex2html/icons/crossref.png) ) y cada una de las colas de prioridad para los puntos que no
son pivotes son rellenadas con los pivotes más cercanos véase
esto en la figura , con esto se asegura que los
vecinos más cercanos estén dentro del radio inicial, el cual está acotado por los
pivotes, véase la figura
) y cada una de las colas de prioridad para los puntos que no
son pivotes son rellenadas con los pivotes más cercanos véase
esto en la figura , con esto se asegura que los
vecinos más cercanos estén dentro del radio inicial, el cual está acotado por los
pivotes, véase la figura
A continuación se presentan de manera detallada las ideas mencionadas anteriormente.
- Inicialización de la cola de prioridad.- En esta primera etapa, cada
elemento de la base de datos, no cuenta con ningún elemento en su
cola de prioridad, y su radio de búsqueda inicial es infinito, así que se
toman todos los pivotes con los que se generó el FQTrie y se
inicializan las colas de prioridad de todos los elementos, debido a que estos
conocen las distancias a todos los elementos de la base de
datos, con esto se reduce el radio máximo en la cola de prioridad,
es decir, de un radio infinito a un radio acotado por los pivotes,
inicialmente se tienen al menos posibles elementos a ser los
vecinos más cercanos en la cola de prioridad, es decir, todos los puntos que
nos pivotes, en su cola de prioridad tienen a sus pivotes más cercanos
(esto es solo inicialmente). Esta etapa puede verse en la
figura .
Figura:
Cola de prioridad inicializada. En la figura se muestran
algunos puntos (parte izquierda) con sus radios máximos en la cola de prioridad
(parte derecha), con
círculos entorno al elemento.
|
|
- Consulta de rango para cada punto.- Una vez que se cuenta con
un radio inicial en la cola de prioridad de cada elemento, se inicia la
construcción de los vecinos más cercanos. Primero, se toma un
punto a la vez, y se hace una consulta de rango sobre el índice
construido con
este elemento y su radio máximo en la cola de prioridad, usando los pivotes
con los que se construyó el índice; esto se hace así para
cada elemento de la base de datos, es importante enfatizar que a
medida que una consulta de rango es aplicada a un elemento, todos los
cálculos de distancia realizados en esta consulta, sirven para
actualizar el radio máximo de las otras colas de prioridad, no solo
la del elemento actual.
Cada vez que se encuentra un elemento que mejora la distancia
máxima (es decir, es una distancia más pequeña) de alguna cola de
prioridad, se saca el elemento
en el tope de la cola de prioridad y se inserta el elemento encontrado, con esto
obviamente se reduce el radio máximo de la cola de prioridad. El algoritmo termina
cuando a todos los elementos de la base de datos se les aplico esta
consulta, y como resultado todos los elementos ya
tienen sus vecinos más cercanos.
Es importante enfatizar que, debido a las características del
algoritmo, este puede ser detenido en cualquier momento y se tendría una
muy buena aproximación de todos los vecinos más cercanos,
puesto que se mantienen siempre al menos elementos más
cercanos durante el desarrollo del algoritmo.
Next: Ejemplo
Up: Encontrando todos los vecinos
Previous: Encontrando todos los vecinos
Índice General
Karina Mariela Figueroa Mora
2001-07-02